Download all your website’s links to improve your SEO via content clusters
Disclosure: This post may contain links to affiliate partners and products, that I have selected manually and would or have bought myself. I will get a commission if you decide to purchase anything after clicking on these links – at no cost to you.
This technique is very helpful if you want to organise your website’s content into content clusters (hubs) better. It will give you a visual way of all the links and how they cluster that you can use to further improve your SEO.
Step 1 – get a list of all links on your website
Method 1: Download your sitemap manually
A sitemap will list all your public content URLs (basically anything Google crawls). It is usually something like this:
- yourwebsite.com/sitemap.xml
- yourwebsite.com/sitemap_index.xml
You will have to open each post-type link and select all URLs it contains and copy it manually to a file.
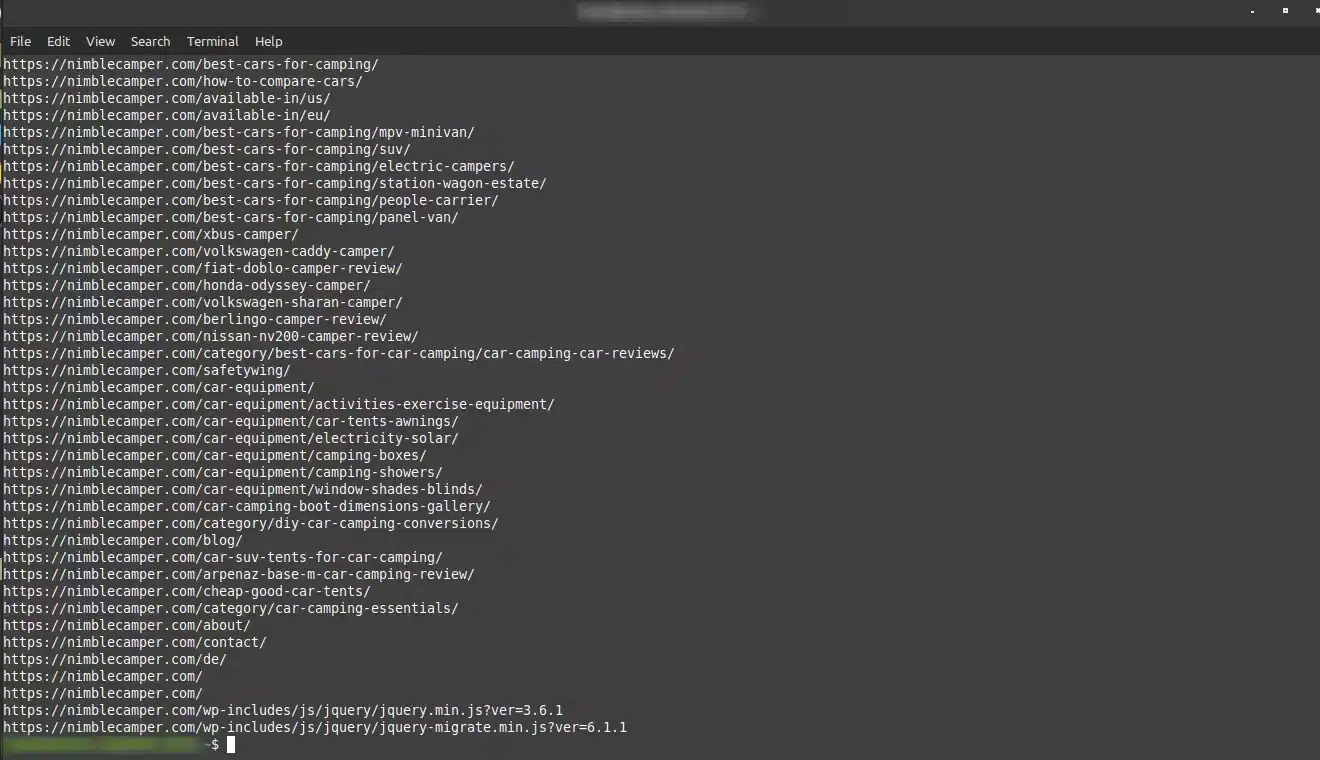
Or – you could use this command to do it for you:
wget -qO- https://yourwebsite.com/sitemap_index.xml | grep -o '<loc>[^<]*</loc>' | sed 's/<loc>\|<\/loc>//g' | xargs -n 1 wget -qO- | grep -o '<loc>[^<]*</loc>' | sed 's/<loc>\|<\/loc>//g' | tee links.csvIn this command, the tee command is added at the end of the pipeline to write the output to a file called links.csv. This command will both output the URLs to the console and save them to the CSV file.
If you want to overwrite the file every time you run the command, use a single > instead of tee:
wget -qO- https://nimblecamper.com/sitemap_index.xml | grep -o '<loc>[^<]*</loc>' | sed 's/<loc>\|<\/loc>//g' | xargs -n 1 wget -qO- | grep -o '<loc>[^<]*</loc>' | sed 's/<loc>\|<\/loc>//g' > links.csvMethod 2: Using an online tool
One way to visualize all the links on your website is to use an online tool such as Ahrefs Site Explorer, Screaming Frog SEO Spider (free up to 500 URLs), or SEMrush Site Audit. These tools will crawl your website and provide you with a list of all the internal and external links on your site, along with other useful information like broken links, duplicate content, and more.
HTTrack is completely free – you should be able to install it via your Linux Software Manager.
These tools give you a better type of output with more granular data – the relationship between your links, i.e. what page links to what other page. This helps further down the line to see your current content clusters. The other methods in this post will only give you a single-column list (dump) of all the internal links on your website, which you will have to categorise yourself first. This is, of course, easily doable using Google Sheets/Excel commands to filter out certain strings (like category, tag or product attribute slugs).
Here’s how you can use Ahrefs Site Explorer to visualize all the links on your website:
- Go to https://ahrefs.com/site-explorer.
- Enter your website’s URL (nimblecamper.com) in the search bar and click the search button.
- Once the report is generated, click on the “Backlinks” tab.
- Under the “Internal” section, you will see a list of all the internal links on your website.
- Export them as a .csv document
Method 3: Using Linux commands
Another way to visualize all the links on your website is to use the command line in Linux. Here’s how you can do it:
- Open a terminal window on your Linux machine.
- Use the wget command to download your website’s HTML files: (replace yourwebsite.com with your actual domain)
wget --recursive --level=1 --no-clobber --page-requisites --convert-links --no-parent -R jpg,jpeg,png,gif,css,js,mp4,avi,flv,webm,xml,webp,ttf,otf,eot,woff,woff2,pdf https://yourwebsite.comThis will download all the HTML files from your website and convert all the links to relative links. This process will run for several minutes or much longer if you have a high number of posts and pages on your website.
The result will be a local copy of your entire website (excl. any images of course – those will mostly work as they will be pulled from their original online URLs). You can then browse the website by opening the index.html file in the downloaded folder, for example:
file:///home/lukas/nimblecamper.com/index.htmlThe website will download to your home directory: /home/yourlogin/yourwebsite.com/
The -R option is used to exclude files with the extensions jpg, jpeg, png, gif, css, js, mp4, avi, flv, webm, xml, webp, ttf, otf, eot, woff, woff2, and pdf. This will prevent wget from downloading files with these extensions from your website and therefore (mostly) provide URLs of frontend pages and posts only. You might need to run this a few times and refine the -R extensions to exclude to get the best final result.
Or alternatively, you can use the ‘curl‘ command:
curl -s https://yourwebsite.com | grep -Eo "(http|https)://yourwebsite\.com[a-zA-Z0-9./?=_%:-]*"In this modified command, the -o option is used to extract only the matched parts of the regular expression, which is the URLs that include the nimblecamper.com domain. The regular expression "(http|https)://nimblecamper\.com[a-zA-Z0-9./?=_%:-]*" matches all URLs that start with “http://” or “https://” and include the nimblecamper.com domain, followed by any combination of letters, numbers, and characters that are commonly found in URLs.
To take it a step further, you can combine the curl and grep commands to exclude subfolders like /wp-content/, making sure you don’t get URLs of your images for example:
curl -s https://yourwebsite.com | grep -Eo "(http|https)://yourwebsite\.com[a-zA-Z0-9./?=_%:-]*" | grep -v "/wp-content/"In this modified command, the first part is the same as the previous command, which uses the -o option with a regular expression to match only the URLs that include the nimblecamper.com domain.
The second part of the command uses the grep command with the -v option to exclude any URLs that include the “/wp-content/” subfolder. The output of the first part is piped to the second part, and the second part filters out any URLs that include the subfolder.
By using this modified command, you will only see the URLs from the nimblecamper.com domain that do not include the “/wp-content/” subfolder in the output. This can be useful if you want to focus only on the pages and posts on your own website, without being distracted by URLs for media files or other content in the “/wp-content/” subfolder.
- Use the grep command to search for all the links in the downloaded HTML files:
grep -o 'href="[^"]*"' yourwebsite.com/*.htmlThis will output a list of all the links in the downloaded HTML files.
- Save the output to a file, you can redirect the output to a file:
grep -o 'href="[^"]*"' yourwebsite.com/*.html > links.txtThis will save the list of links to a file called links.txt in the current directory.
Step 2 – Visualise the links in a flowchart with clusters
- Export the list of links to a text file. You can do this by using the command line in Linux, as described in the previous answer, or by using an online tool to export the list of links to a CSV or Excel file.
- Import the list of links into a flowchart software that supports clusters. One option is to use software like Lucidchart (free plan available), which allows you to create flowcharts and group related nodes into clusters. Or Gephi (but the steps below will differ)
- Start by creating a node for the homepage of your website. This will be the starting point of your flowchart.
- Add nodes for each of the internal links on your website, and connect them to the homepage node using arrows. You can group related links into clusters by creating boxes or shapes around them.
- Continue adding nodes for each of the internal links on your website, and connecting them to the appropriate nodes. You can use different colours or shapes to differentiate between internal and external links.
- Once you’ve added all the nodes and links, you can rearrange them to create a clear and organized flowchart. You can also add labels, descriptions, or annotations to provide additional context.
By following these steps, you can create a flowchart with clusters that visualizes all the links on your website. This can be a useful tool for identifying any broken links, orphaned pages, or areas of your website that may need improvement.
Alternative – Visualise the content clusters in Mindmeister.com
This might be helpful for a lower number of links – you can manually draw a map of your core topics and their relationships easily using mindmeister.com (free plan available) and then assign all links to those categories.

Best theme for building websites efficiently
Get 10% off
any Kadence product: Theme, Plugins, Cloud or full Bundle
- great customer service & support
- super header & footer builder
- performance optimised
- Gutenberg, Elementor, Beaver Builder, Woocommerce, LearnDash, The Events Calendar & more integrations
- Supercharge your website development with Hooked Elements (Premium)
Use this code at checkout:
nimble10